



はじめまして、クリエイティブ事業部のOkuboです。
グラフィックとウェブのデザイン制作を担当しています。
はじめに
このブログでは、主にAIプロンプトと書体(タイポグラフィ)の話をしていきたいと思っています。両者は一見するとまったく違うテーマのようですが、どちらも「言語」が深く関わるものです。
AI(LLM)プロンプトは、言語によるインプットから、それに対するアウトプットを得る営み。一方で書体(タイポグラフィ)は、言語記号である文字そのものの姿をデザインする営み。
つまり、片方は「言葉をどう投げかけるか」、もう片方は「言葉をどう見せるか」という関係にあります。
デザインとは、「伝えたいことを、もっとも伝わるかたちに変換する行為」です。
時にそれは色や形であり、時に言葉の選び方や文字の姿そのものでもあります。
AI(LLM)が生成する表現と、ヒトが積み重ねてきた文化。この両極から「言葉とデザイン」について実践や引用を交えつつ、感じたことをゆるめに綴っていきたいなあと思います。
ChatGPT-5に「小学校1・2年生の漢字だけ」で文を書き換えてもらう
では早速、まずは直近でAIに処理してもらった、ちょっと変わった事案について。
あるイベントで使う、夏休みの子ども向けクイズの問題文を、当初全て「ひらがな」で作成しました。
(イベント詳細はこちら。未就学児〜小学生のお子様とご家族で楽しめる無料アトラクションを複数ご用意しています!)
小さな子たちにも読んでもらうことを意識して、あえて漢字を避けたのですが…クライアントから返ってきた要望はこうでした。
「小学1・2年生が習う漢字は、ちゃんと使ってほしい」
…なるほど。確かに該当のクイズは未就学の子にはちょっとレベルの高い内容だし、小学生にとっては「習ったはずの漢字が全部ひらがなになっている」のは逆に読みにくく、学習的にももったいないよね、と気づかされました。
でも、一字一字を確認しながら手動で書き換えていくのはたいへんだなあ、ということで、ここはAIに。公開ほやほやのChatGPT-5に文を自動で書き換えてもらうことを試みました。
書き換えてもらいたい内容は全部で10段落。それぞれの段落は、4〜10文節から構成される1〜2文となっています。
漢字配当表をウェブから参照する
まず最初に、小学校1・2年生の漢字をAIに認識してもらう必要があります。
文部科学省のサイトに小学校学習指導要領の別表として「学年別漢字配当表」が掲載されていますので、それを参照した上で、試しに1段落分だけ書き換えてもらうことにしました。
初手のプロンプトはこちら。
https://www.mext.go.jp/a_menu/shotou/new-cs/youryou/syo/koku/001.htm
上記のURLを参照し、第一学年・第二学年の漢字を以下の文章に適用してください。
アクアマリンふくしまが、ゆうめい。うみやかわの いきものを、ちかくで みたり さわったりできるばしょ。プラスチックごみの もんだいも まなべるよ。
GPT-5の解答は、
アクアマリン福島が、有名。海や川の 生き物を、近くで 見たり さわったりできる場所。プラスチックごみの 問題も 学べるよ。
1・2年生で習わない漢字が多数混在しています。ちゃんと参照していませんね。多分、学年別漢字配当表内の1〜6学年全ての漢字を適用してしまっているのでしょう。
なので、1・2学年の漢字だけ適用することを再度プロンプトで強調します。
**第一・第二学年の漢字だけ適用**です。ちゃんと見直して正確に書き換えてください。
GPT-5の解答がこちら。
アクアマリンふくしまが、ゆうめい。海や川の 生きものを、近くで 見たり さわったりできるばしょ。プラスチックごみの もんだいも 学べるよ。
今度は良さげです。では、この調子で残りの全段落を一気に書き換えてもらいましょう。
改めて該当漢字をテキストで認識させる
ところが実際やってみると…
(※一部抜粋)
なつ から あきにかけて、つよいかぜと 大あめで まちがこわれたり、
人がケガしたりする あらしのこと。
「ちきゅうおんだんか」がすすむと、ふえちゃうんだ!
おかいもので、ビニールぶくろは もらわない。
自分で 入れるものを よういして、くりかえし つかおう!
海の ふかーいところにいる、さかなたちのこと。プラスチックごみが
ふかーい 海までとどくと、100ねんたっても ずっと のこってしまうんだ。
あれ?今度はひらがなだらけ。明らかに適用が不十分なのがわかります。
1・2学年の漢字、やっぱりちゃんと認識できていない?URLから参照させるのは、現時点のAIには荷が重かったか…(GPT-5に期待しすぎたかな)。
ちゃんと参照部分をテキストで認識させる必要がありそうです。漢字配当表から該当部分をコピペして参照させましょう。
**漢字一覧は以下を参照し、ちゃんと認識したうえで正確に書き換えてください。**
◆第一学年
一右雨円王音下火花貝学気九休玉金空月犬見五口校左三山子四糸字耳七車手十出女小上森人水正生青夕石赤千川先早草足村大男竹中虫町天田土二日入年白八百文木本名目立力林六
◆第二学年
引羽雲園遠何科夏家歌画回会海絵外角楽活間丸岩顔汽記帰弓牛魚京強教近兄形計元言原戸古午後語工公広交光考行高黄合谷国黒今才細作算止市矢姉思紙寺自時室社弱首秋週春書少場所色食心新親図数西声星晴切雪船線前組走多太体台地池知茶昼長鳥朝直通弟店点電刀冬当東答頭同道読内南肉馬売買麦半番父風分聞米歩母方北毎妹万明鳴毛門夜野友用曜来里理話
(※一部抜粋)
夏から 秋にかけて、強い風と 大雨で 町がこわれたり、
人がケガしたりする あらしのこと。
「ちきゅうおんだんか」が すすむと、ふえちゃうんだ!
お買い物で、ビニールぶくろは もらわない。
自分で 入れるものを よういして、くりかえし つかおう!
海の ふかーいところにいる、魚たちのこと。プラスチックごみが
ふかーい 海まで とどくと、100ねんたっても ずっと のこってしまうんだ。
一見すると、きちんと書き換えられていそうですが…。
- 「ちきゅうおんだんか」の「ち」は、第二学年に「地」の配当あり
- 「お買い物」の「物」は、第三学年の配当なので誤適用
- 「100ねん」の「ねん」は、第一学年に「年」の配当あり
書き換えの精度がまだまだ甘いです。
書き換えのルールをAI自身に明文化させる
この「書き換えのブレ」を解消するために、AIに変換ルールを明文化させることにしました。まず第一学年・第二学年の漢字配当表をAI自身に作成させ、その上で、変換漏れや誤変換を防止するためのルールを提示してもらいます。
その結果、GPT-5が提示した変換ルールは、
- 入力テキストを一文字ずつ判定。
- 文字が上記の第一・第二学年漢字リストにあれば そのまま漢字。
- それ以外の漢字(第三学年以上の配当漢字や常用外漢字)は ひらがなに変換。
- 数字(例: 100)はそのまま残す。
- 熟語内でも、一方が対象漢字で他方が対象外の場合、対象外はひらがなにする。
さらに、GPT-5が自発的に、このルールをPHPの簡易コードにして書き出してくれました。かわいい。
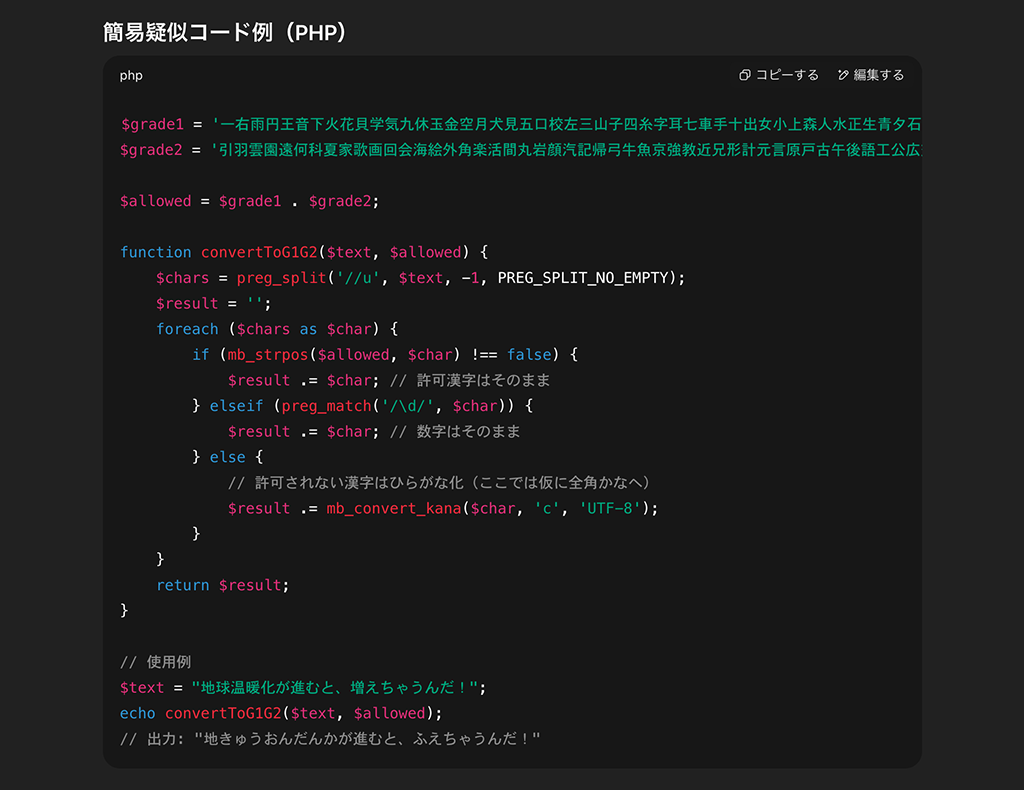
ルールの明文化で誤変換が解消
このルールで、改めてGPT-5に文を書き出してもらいます。さて、どうでしょう?
(※一部抜粋)
夏から 秋にかけて、強い風と 大雨で 町がこわれたり、
人がケガしたりする あらしのこと。
「地きゅうおんだんか」が すすむと、ふえちゃうんだ!
お買いもので、ビニールぶくろは もらわない。
自分で 入れるものを よういして、くりかえし つかおう!
海の ふかーいところにいる、魚たちのこと。プラスチックごみが
ふかーい 海まで とどくと、100年たっても ずっと のこってしまうんだ。
ようやくパーフェクトな解答が得られました。全10段落、すべての文に第一・第二学年の配当漢字のみが適用されていることが確認できたので、ここでミッション完了です。
実は、初手はClaudeのほうが上手(うわて)だった
面白いお題でしたので、Claude(Sonnet 4)にも同じ処理を同じ流れで試みました。
その結果、Claudeは初手の時点で、参照URLの配当表から第一・第二学年の配当漢字を引用し、自発的にテキスト化してから該当文を書き換えるという手順を見せてくれました。
うん、おりこう。もしかすると、この処理はClaudeのほうが優位なのでは。
このまま残りの全段落を、一気に書き換えてもらおうとしましたが…あれ?
他学年の漢字が混ざっていたり、第一・二学年の漢字が抜けてしまっていたり。うまく書き換えられていません。
ChatGPT-5とClaudeの躓きから見る、AI側・プロンプト側それぞれの課題
その後は若干の差異こそあれ、GPT-5とかなり似通った躓きを経ましたので、この事例から導き出されるAI側の課題と、プロンプトを投げる人間側の課題をまとめました。
AI側の課題
1. 情報の正確な参照・適用の不備
漢字配当表を正しく取得できなかった。あるいは取得できたにも関わらず、実際の適用時に別学年の漢字を混入させてしまう。
2. 段階的な検証プロセスの欠如
「この漢字は本当に第一・二学年に含まれているか」という検証がなされていない。
3. 過度な推測と不正確な修正
間違いを指摘されると、正しい判断まで疑って過剰に修正してしまう。
4. 一貫性の欠如
同じタスクを繰り返す際に、前回の正しい判断基準を維持できない。
人間側(プロンプト)の課題
1. 初期指示の具体性不足
「第一・二学年の漢字を適用」という指示だけでは、詳細な条件が不明確だった。
2. 段階的な難易度設定
2手目でいきなり長文を依頼せず、もっと段階的に難易度を上げるべきだった。
3. エラー時の具体的フィードバック
「間違っている」だけでなく「どの漢字がどう間違っているか」の具体的な指摘が必要。
※AIの共通特性:「初手優位性」の罠
興味深かったのは、Claudeの初手の優位性が結果的に意味をなさなかったことです。
つまり、以下に挙げたこれらの要素は、AI全般において意識するべき共通特性かもしれません。
- 最初にうまくできると、「理解している」と人間側が錯覚
- タスクが複雑になると参照情報を継続的に活用する能力が低下
- 人間なら「慣れ」で改善するが、AIは逆に「慣れ」で劣化することがある
まとめ
今回の試みから得たのは、AIの出力には持続的な正確性の維持に課題があるということです。
特に留意する点として、
- 複雑なタスクほど段階的なアプローチが重要
- 初期の成功に惑わされず、継続的な検証が必要
- 具体的で明確な指示と、細かなフィードバックが効果的
これらの具体的な対応策としては、
- 詳細な条件明示:「学年別漢字配当表に完全準拠」など具体的基準を提示
- 段階的な確認:簡単な例で理解度を確認してから段階を経て大きいタスクに進む
- 即座の具体的フィードバック:エラー箇所を具体的に指摘
といったところでしょうか。
「AIに任せきり」ではなく「一緒にルールを育てながら作業する相棒」として使うのが正解だな、とあらためて感じた事例でした。